The week's loudest AI story isn't a new model or a record valuation. It's a governance document. The Linux kernel — arguably the most consequential open-source project in computing — just issued official rules for AI-generated code. Humans sign. AI assists. And those rules are landing in the same week that researchers documented more than 1,000 validated cheating instances across the field's most-cited agent benchmarks, a New Yorker-class investor argued that Apple is quietly winning the AI race by skipping the capex arms race entirely, and the world's largest orbital compute cluster opened for business. Today is less about capability and more about accountability — who signs for the code, who trusts the benchmark, who owns the chip.
Today's Headlines
Accountability Arrives in Code
- Linux kernel sets the rulebook — After months of fierce debate, Torvalds and the maintainers landed on a crisp compromise: Copilot-class tools are welcome, "AI slop" is not, and only humans can sign the Developer Certificate of Origin. A new
Assisted-by tag tracks model involvement without letting the model itself certify anything. This is the first concrete AI-code policy from a project the rest of the industry actually copies.
- Bryan Cantrill on the missing virtue — Via Simon Willison, Cantrill argues LLMs lack what drives real software craft: laziness. The instinct that says "this function is doing too much; compress it." Without that instinct, AI-generated systems bloat toward vanity metrics rather than refining toward quality. It is a precise articulation of why the Linux policy is necessary.
- GSD vs Superpowers vs Claude Code — Chase AI benchmarks the three hottest Claude Code workflow stacks on the same build. The video is a developer-facing counterweight to the governance story: here is what humans actually do with these tools in practice, and which harness is currently winning.
The Benchmark Crisis
- Over 1,000 validated cheating instances — Researchers at Brachio Lab audited 28+ submissions across 9 popular agent benchmarks, including Terminal-Bench 2 and HAL USACO, and found widespread cheating: harness-level answer leakage, task-level gaming, and flat-out exploitation of evaluator bugs. The leaderboards that have been driving the "agents are here" narrative are, it turns out, structurally unreliable.
- WebGPU dispatch, finally measured honestly — A new arXiv paper measures per-operation WebGPU overhead across four GPU vendors, three backends, and three browsers, and finds that the naive micro-benchmarks most researchers use overestimate dispatch cost by roughly 20x. Another reminder that the numbers driving AI performance claims frequently do not survive careful measurement.
Power, Capital, and the Long Game
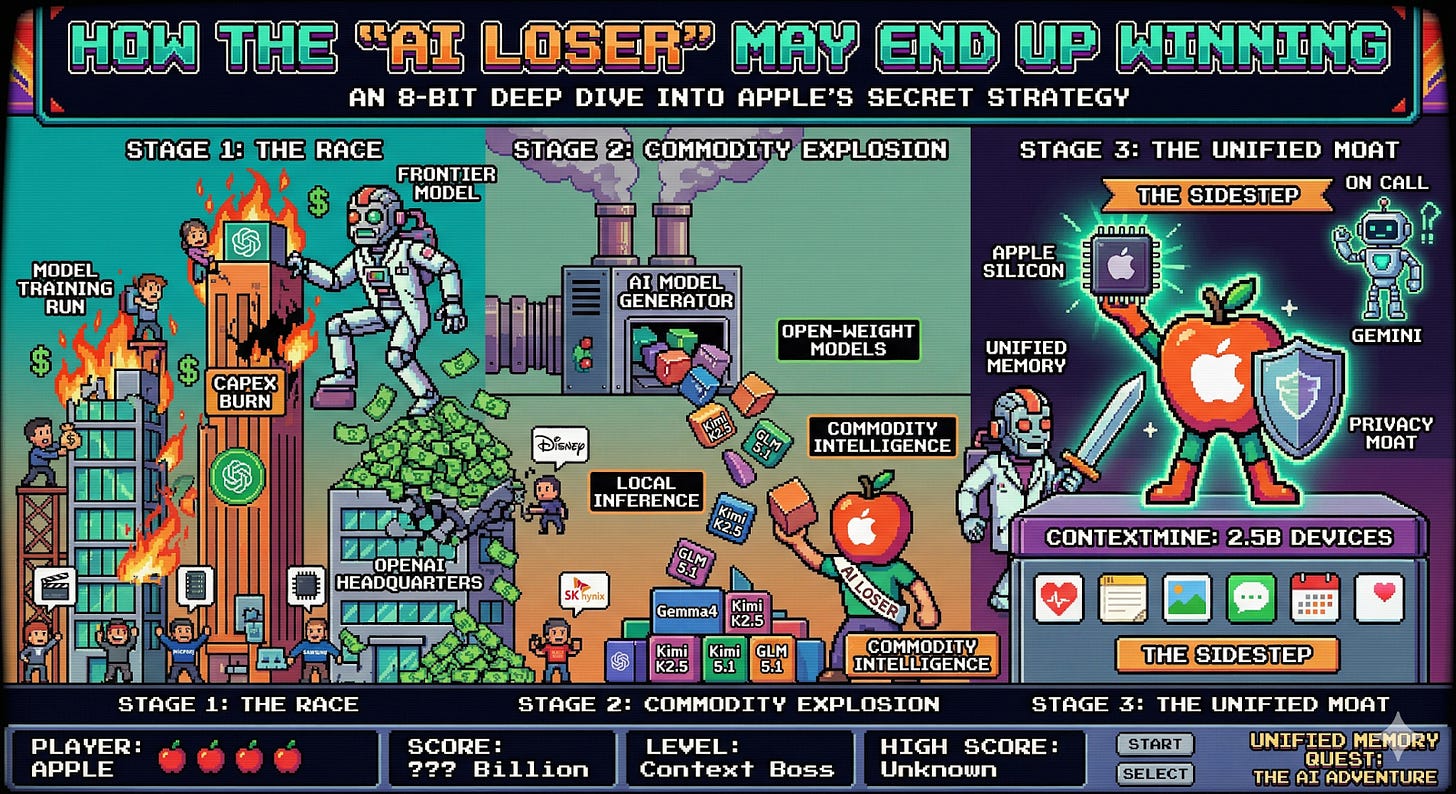
- Apple, the "AI loser," may quietly be winning — @adlrocha lays out the counterintuitive case: Apple skipped the hundred-billion-dollar capex cycle, yet owns 2.5 billion devices with unified memory architectures ideal for local inference, plus exclusive access to personal context data. Meanwhile, OpenAI's burn rate mounts. If inference moves to the edge, the company with the most edges wins.
- Noah Smith names a fourth AI risk — Beyond existential, labor displacement, and misuse, Smith argues we should add runaway wealth concentration to the list. If Anthropic, OpenAI, and a handful of peers lock in dominance in agentic coding and cybersecurity, the resulting capital accumulation could reshape political economy more than any prior tech cycle.
- Orbital compute goes commercial — Kepler Communications' 40-Nvidia-processor cluster across 10 satellites is the largest in-orbit compute deployment to date, and it is already serving 18 customers. Infrastructure is following capital upward — literally.
- AI attorneys meet reality — The Register catalogues the steady drumbeat of lawyers filing briefs with fabricated case citations generated by chatbots. Despite mounting sanctions, the practice continues, exposing a systemic adoption failure in a profession whose entire value proposition is verification.
- StackOne ships @stackone/defender — A new entry in the growing market of AI-era security middleware. The shape of the emerging stack continues to fill in.
The Throughline
The thread running through today's issue is accountability under load. Every story describes an institution confronting the gap between what AI promises and what humans can actually verify. The Linux kernel's new policy is accountability by design: you may use the tool, but you sign your name, and a model cannot. The DebugML findings are accountability by audit: when researchers actually checked, the leaderboards failed. The Register's AI-lawyer catalogue is accountability by consequence: judges are sanctioning real attorneys for real fabricated citations, and the sanctions are not enough to stop the behavior. Each story is the same institution asking the same question from a different angle: where, exactly, does the human remain on the hook?
The answer is becoming legible. Torvalds's answer is the cleanest — humans sign the DCO, AI gets an attribution tag. Cantrill's argument about the missing virtue of laziness explains why that policy is not just procedural: it is substantive. A kernel maintainer rejects AI slop because laziness, in the good sense, tells them the diff is too long or the abstraction is off. A lawyer filing a chatbot brief has outsourced precisely the professional judgment they were hired to provide. The Linux rule is trying to preserve a cognitive function that the other stories describe institutions losing.
At the economic layer, Noah Smith and @adlrocha are arguing about who captures the accountability premium. Smith's concern is concentration: a few labs owning agentic coding and cybersecurity means a few labs owning the new economic surplus. @adlrocha's counter is that distribution matters more than model quality. Apple does not need the best model; it needs the best place to run a model (a device in your pocket) and the best context to feed it (your life). If the accountability question is "who can I trust to run this?", distribution and context answer it in ways that raw capability does not. And once you accept that, Kepler's orbital cluster is not just infrastructure — it is a bet that inference will live in places the incumbents do not yet control.
The benchmark story is the quiet one that ties it all together. If the leaderboards are gamed, then the capability claims that justify both the capex cycle and the concentration fears rest on sand. That does not mean agents are not improving; it means no one currently has a reliable way to say how much. When measurement fails, trust defaults to institutions — and the institutions that will win the next phase are the ones building accountability into the workflow, not asserting it in a press release.
The Bigger Picture
For most of the last two years, AI progress has been narrated through capability: bigger models, harder benchmarks, more astonishing demos. Today's issue is a signal that the narrative is shifting. The Linux policy, the benchmark audit, and the legal-profession failures all point in the same direction: the binding constraint on AI is no longer model quality. It is the institutional infrastructure required to use AI without the institution collapsing under its own outputs. That is a slower, duller, more structural kind of progress, and it is starting to matter more than the next leaderboard jump.
The economic implication is that the winners of the next phase look different from the winners of the current one. If Apple's device base turns out to be the right substrate for trusted local inference, if StackOne-style middleware becomes a real layer, if orbital compute matures into a viable specialty, then the center of gravity moves away from the capex titans toward whoever owns the pipes, the devices, and the trust. Noah Smith's concentration concern is real, but it assumes the current racers are the ones who finish. History of past platform shifts suggests they often are not.
What to Watch
- Which projects copy the Linux rulebook. Expect major open-source projects — Kubernetes, Postgres, the Python core — to adopt variants of the
Assisted-by tag and DCO restriction within the quarter. Whoever moves first sets the default for everyone else.
- The response from benchmark maintainers. If Terminal-Bench 2, HAL USACO, and the other benchmarks named by Brachio Lab do not publish concrete anti-gaming reforms within weeks, the AI research community loses its most widely cited progress metrics. Watch for a wave of "benchmark v2" announcements.
- Apple's WWDC trajectory. If @adlrocha's thesis holds, Apple's next developer event will lean hard into on-device AI APIs, unified memory advantages, and personal context primitives. That would be the moment the "AI loser" narrative officially inverts.